NLP实验-RAG-251113
目录
- 零、相关补充说明
- 一、实验内容
- 二、实验步骤
- 2.6 RAG 链核心模块详解(chains/rag_chain.py)
- 完整样例代码
- 2.6.1 RAGChain 类初始化
- 2.6.2 构建向量存储:
build_vector_store() - 2.6.3 加载向量存储:
load_vector_store() - 2.6.4 构建 RAG 链:
_build_chain() - 2.6.5 格式化文档:
_format_docs() - 2.6.6 查询函数:
query() - 2.6.7 添加文档:
add_documents() - 2.7 主程序模块详解(main.py)
- 2.8 实验步骤1:安装依赖
- 2.9 实验步骤2:构建向量存储
- 2.10 实验步骤3:交互式查询
- 2.11 实验步骤4:单次查询
- 2.12 实验步骤5:使用自定义文档
- 三、实验任务
零、相关补充说明
0.1 源码和实验手册
下载链接:rag_starter.zip
下载保存时改个文件名,比如rag_starter.zip。
用可以直接下载保存到开发板上。比如,保存到 /home/cg/ailab。
依次执行以下命令,将 zip 包解压缩:
cd /home/cg/ailab # 假定 zip 文件保存在 /home/cg/ailab 目录
ls -l # 确认下 zip 文件是否在该目录中
unzip rag_starter.zip # 假定 zip 文件名是rag_starter.zip
0.2 各个目录下的 init.py
项目根目录 ./__init__.py
"""
RAG Starter - 基于 LangChain 的 RAG 系统
"""
__version__ = "1.0.0"
chains/__init__.py
"""
RAG 链模块
"""
from .rag_chain import RAGChain
__all__ = ["RAGChain"]
config/__init__.py
"""
配置模块
"""
from .settings import settings
__all__ = ["settings"]
models/__init__.py
"""
模型模块 - 导出 LLM 和嵌入模型
"""
from .llm import get_llm
from .embedding import get_embedding_model
__all__ = ["get_llm", "get_embedding_model"]
utils/__init__.py
"""
工具模块 - 导出文档加载器
"""
from .document_loader import load_documents, split_documents
__all__ = ["load_documents", "split_documents"]
0.3 装 vscode
- 访问 vscode 官网。
- 下载 ubuntu arm64 .deb。
- 执行
sudo dpkg -i 下载的包名.deb安装。
0.4 本地笔记本装 MobaXterm
下载链接:MobaXterm_Portable_v25.3.zip
下载到笔记本,解压缩后就可运行。
可通过笔记本连接开发板。
一、实验内容
1.1 实验内容
本实验将使用 RAG(Retrieval-Augmented Generation,检索增强生成)系统进行知识问答实验。RAG 是一种结合了信息检索和生成式 AI 的技术,通过从知识库中检索相关信息来增强大语言模型的回答能力。本实验将学习如何构建一个完整的 RAG 系统,包括文档加载、向量化存储、相似度检索和答案生成等核心模块。
1.2 实验要点
- 了解 RAG 系统的基本原理和工作流程
- 学习 LangChain 框架的使用方法
- 掌握文档加载、文本分割、向量化存储等关键技术
- 学会使用 FAISS 进行高效的向量检索
- 理解如何将检索到的上下文信息与大语言模型结合生成答案
1.3 实验环境
- Python 3
- LangChain 框架
- FAISS 向量数据库
- Qwen 大语言模型(通过 API 端点访问)
二、实验步骤
2.1 RAG介绍
RAG(检索增强生成)系统是一种结合了信息检索和生成式 AI 的先进技术。其核心思想是:当用户提出问题时,系统首先从知识库中检索相关的文档片段,然后将这些上下文信息与大语言模型结合,生成更准确、更有依据的答案。相比直接使用大语言模型,RAG 系统能够:
- 提供事实依据:答案基于实际文档内容,而非模型训练数据
- 减少幻觉:通过检索到的上下文约束,降低模型编造信息的可能性
- 支持知识更新:只需更新知识库,无需重新训练模型
- 提高准确性:针对特定领域的知识库能够提供更专业的回答
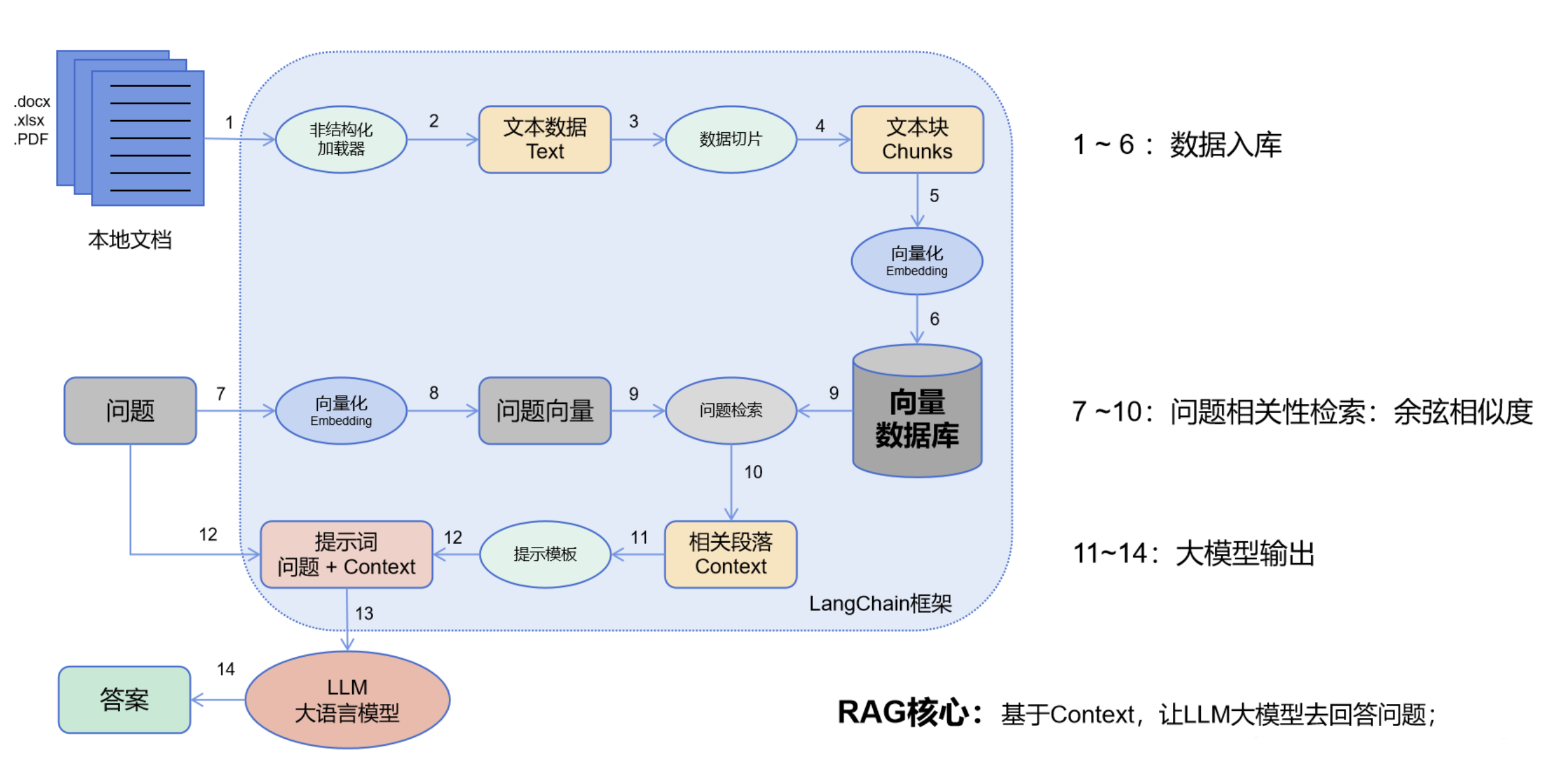
主要流程:
-
数据入库:读取本地数据并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中(图1~6步);
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context(图7~10步);
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动(图11~15步)
本实验使用的 RAG 系统基于 LangChain 框架构建,采用模块化设计,代码结构清晰,便于理解和扩展。
2.2 项目结构介绍
本项目的代码采用模块化设计,主要包含以下目录和文件:
rag_starter/
├── config/ # 配置模块
│ ├── __init__.py
│ └── settings.py # 配置文件
├── models/ # 模型封装
│ ├── __init__.py
│ ├── llm.py # LLM 模型封装
│ └── embedding.py # 嵌入模型封装
├── chains/ # RAG 链
│ ├── __init__.py
│ └── rag_chain.py # RAG 链实现
├── utils/ # 工具函数
│ ├── __init__.py
│ └── document_loader.py # 文档加载工具
├── vectorstore/ # 向量存储目录(自动生成)
├── main.py # 主程序入口
├── requirements.txt # 依赖文件
├── kb.txt # 示例知识库文件
└── handbook.md # 本实验手册
2.3 配置模块详解(config/settings.py)
配置模块负责管理整个系统的配置参数,使用 pydantic-settings 库实现配置管理。
样例代码
"""
配置文件 - 存储模型端点和其他配置信息
"""
from typing import Optional
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
"""应用配置"""
# LLM 模型配置
LLM_BASE_URL: str = "http://172.18.144.18/svc/DGsanOif-1/v1"
LLM_MODEL_NAME: str = "qwen2.5:32b"
LLM_API_KEY: str = "EMPTY"
LLM_TEMPERATURE: float = 0.7
LLM_MAX_TOKENS: int = 2048
# 嵌入模型配置
EMBEDDING_BASE_URL: str = "http://172.18.144.18/svc/97iYTIRw-1/v1"
EMBEDDING_MODEL_NAME: str = "qwen3-embedding:8b"
EMBEDDING_API_KEY: str = "EMPTY"
EMBEDDING_DIMENSION: int = 1024 # 根据实际模型调整
# 向量存储配置
VECTOR_STORE_PATH: str = "./vectorstore"
CHUNK_SIZE: int = 1000
CHUNK_OVERLAP: int = 200
# 检索配置
TOP_K: int = 4 # 检索相关文档数量
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
# 全局配置实例
settings = Settings()
配置参数说明
- LLM 模型配置
LLM_BASE_URL: 大语言模型的 API 端点地址LLM_MODEL_NAME: 使用的模型名称LLM_TEMPERATURE: 生成温度,控制输出的随机性(0-1,值越大越随机)LLM_MAX_TOKENS: 最大生成 token 数,限制答案长度
- 嵌入模型配置
EMBEDDING_BASE_URL: 嵌入模型的 API 端点地址EMBEDDING_MODEL_NAME: 嵌入模型名称EMBEDDING_DIMENSION: 嵌入向量的维度(1024 维)
- 向量存储配置
VECTOR_STORE_PATH: 向量存储的保存路径CHUNK_SIZE: 文档分块大小(1000 字符)CHUNK_OVERLAP: 分块之间的重叠大小(200 字符),用于保持上下文连贯性
- 检索配置
TOP_K: 检索时返回的最相关文档数量(4 个)
环境变量支持
配置类支持从 .env 文件读取配置,方便在不同环境中使用不同的配置:
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
2.4 模型封装模块详解
2.4.1 LLM 模型封装(models/llm.py)
LLM 模型封装模块提供了统一的接口来获取大语言模型实例。核心函数:get_llm()。
样例代码
"""
LLM 模型封装 - 使用 LangChain 的 ChatOpenAI 兼容接口
"""
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.language_models.chat_models import BaseChatModel
from config.settings import settings
def get_llm(
temperature: Optional[float] = None,
max_tokens: Optional[int] = None,
) -> BaseChatModel:
"""
获取 LLM 模型实例
Args:
temperature: 生成温度,默认使用配置值
max_tokens: 最大生成token数,默认使用配置值
Returns:
LangChain ChatModel 实例
"""
return ChatOpenAI(
base_url=settings.LLM_BASE_URL,
model=settings.LLM_MODEL_NAME,
temperature=temperature or settings.LLM_TEMPERATURE,
max_tokens=max_tokens or settings.LLM_MAX_TOKENS,
api_key=settings.LLM_API_KEY
)
功能说明:
- 使用 LangChain 的
ChatOpenAI类,兼容 OpenAI API 格式 - 支持自定义端点的模型服务
- 可以通过参数覆盖默认配置(temperature、max_tokens)
- 返回的模型实例可以用于生成文本、对话等任务
使用示例:
from models import get_llm
llm = get_llm()
response = llm.invoke("你好")
2.4.2 嵌入模型封装(models/embedding.py)
嵌入模型封装模块提供了获取文本嵌入向量的接口。核心函数:get_embedding_model()。
样例代码
"""
嵌入模型封装 - 使用 LangChain 的 OpenAIEmbeddings 兼容接口
"""
from langchain_openai import OpenAIEmbeddings
from langchain_core.embeddings import Embeddings
from config.settings import settings
def get_embedding_model() -> Embeddings:
"""
获取嵌入模型实例
Returns:
LangChain Embeddings 实例
"""
return OpenAIEmbeddings(
base_url=settings.EMBEDDING_BASE_URL,
model=settings.EMBEDDING_MODEL_NAME,
api_key=settings.EMBEDDING_API_KEY
)
功能说明:
- 使用 LangChain 的
OpenAIEmbeddings类 - 将文本转换为高维向量(1024 维)
- 向量可以用于计算文本之间的相似度
- 支持批量嵌入,提高处理效率
使用示例:
from models import get_embedding_model
embeddings = get_embedding_model()
vector = embeddings.embed_query("这是要嵌入的文本")
嵌入向量的作用:
- 将文本转换为数值向量,便于计算机处理
- 语义相似的文本在向量空间中距离更近
- 支持高效的相似度检索
2.5 工具函数模块详解(utils/document_loader.py)
工具函数模块提供了文档加载和文本分割的功能。
样例代码
"""
文档加载和分割工具
"""
from pathlib import Path
from typing import List, Union
from langchain_community.document_loaders import (
TextLoader,
PyPDFLoader,
UnstructuredMarkdownLoader,
)
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from config.settings import settings
def load_documents(file_path: Union[str, Path]) -> List[Document]:
"""
根据文件类型加载文档
Args:
file_path: 文件路径
Returns:
文档列表
"""
file_path = Path(file_path)
if not file_path.exists():
raise FileNotFoundError(f"文件不存在: {file_path}")
suffix = file_path.suffix.lower()
# 根据文件类型选择加载器
if suffix == ".txt":
loader = TextLoader(str(file_path), encoding="utf-8")
elif suffix == ".pdf":
loader = PyPDFLoader(str(file_path))
elif suffix in [".md", ".markdown"]:
loader = UnstructuredMarkdownLoader(str(file_path))
else:
# 默认使用文本加载器
loader = TextLoader(str(file_path), encoding="utf-8")
documents = loader.load()
return documents
def split_documents(documents: List[Document]) -> List[Document]:
"""
将文档分割成小块
Args:
documents: 原始文档列表
Returns:
分割后的文档列表
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=settings.CHUNK_SIZE,
chunk_overlap=settings.CHUNK_OVERLAP,
length_function=len,
)
split_docs = text_splitter.split_documents(documents)
return split_docs
文档加载函数:load_documents()功能说明:
- 支持多种文件格式:TXT、PDF、Markdown
- 根据文件扩展名自动选择对应的加载器
- 返回 LangChain 的
Document对象列表 - 每个
Document包含page_content(文本内容)和metadata(元数据)
文档加载函数:load_documents()支持的格式:
.txt: 纯文本文件,使用TextLoader.pdf: PDF 文件,使用PyPDFLoader(需要安装pypdf).md/.markdown: Markdown 文件,使用UnstructuredMarkdownLoader
文档分割函数:split_documents()功能说明:
- 使用
RecursiveCharacterTextSplitter进行智能分割 - 按照配置的
CHUNK_SIZE(1000 字符)分割文档 - 使用
CHUNK_OVERLAP(200 字符)重叠,保持上下文连贯性 - 使用len函数作为字符数计算函数
为什么需要分割文档:
- 向量存储限制:大文档无法直接存储为单个向量
- 检索精度:小块的文档片段能够更精确地匹配用户问题
- 上下文管理:只检索相关片段,减少无关信息干扰
2.6 RAG 链核心模块详解(chains/rag_chain.py)
RAG 链模块是整个系统的核心,负责协调检索和生成过程。
完整样例代码
"""
RAG 链实现 - 检索增强生成
"""
from typing import List, Optional
from pathlib import Path
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from models import get_llm, get_embedding_model
from utils import load_documents, split_documents
from config.settings import settings
class RAGChain:
"""RAG 链类,封装检索和生成逻辑"""
def __init__(
self,
vector_store_path: Optional[str] = None,
persist: bool = True,
):
"""
初始化 RAG 链
Args:
vector_store_path: 向量存储路径,默认使用配置值
persist: 是否持久化向量存储
"""
self.vector_store_path = vector_store_path or settings.VECTOR_STORE_PATH
self.persist = persist
self.llm = get_llm()
self.embeddings = get_embedding_model()
self.vector_store: Optional[FAISS] = None
self.retriever = None
self.chain = None
# 创建向量存储目录
Path(self.vector_store_path).mkdir(parents=True, exist_ok=True)
def build_vector_store(self, documents: List[Document], append: bool = False) -> None:
"""
构建向量存储
Args:
documents: 文档列表
append: 如果为 True 且向量存储已存在,则追加文档;否则覆盖
"""
if not documents:
raise ValueError("文档列表不能为空")
# 分割文档
split_docs = split_documents(documents)
# 检查向量存储是否已存在
vector_store_file = Path(self.vector_store_path) / "index.faiss"
if append and vector_store_file.exists():
# 如果启用追加模式且向量存储已存在,则加载并添加文档
print("检测到已存在的向量存储,正在加载...")
self.vector_store = FAISS.load_local(
self.vector_store_path,
self.embeddings,
allow_dangerous_deserialization=True,
)
print(f"正在添加 {len(split_docs)} 个文档块到现有向量存储...")
self.vector_store.add_documents(split_docs)
else:
# 创建新的向量存储(覆盖已存在的)
if vector_store_file.exists():
print("警告: 向量存储已存在,将被覆盖。如需增量添加,请使用 append=True 参数。")
self.vector_store = FAISS.from_documents(
documents=split_docs,
embedding=self.embeddings,
)
# 持久化
if self.persist:
self.vector_store.save_local(self.vector_store_path)
# 创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 构建 RAG 链
self._build_chain()
def load_vector_store(self) -> None:
"""
从磁盘加载向量存储
"""
vector_store_file = Path(self.vector_store_path) / "index.faiss"
if not vector_store_file.exists():
raise FileNotFoundError(
f"向量存储不存在: {self.vector_store_path}。请先调用 build_vector_store() 构建向量存储。"
)
self.vector_store = FAISS.load_local(
self.vector_store_path,
self.embeddings,
allow_dangerous_deserialization=True,
)
# 创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 构建 RAG 链
self._build_chain()
def _build_chain(self) -> None:
"""构建 RAG 链"""
# 定义提示模板
template = """基于以下上下文信息回答问题。如果上下文中没有相关信息,请说明你不知道,不要编造答案。
上下文信息:
{context}
问题:{question}
请提供准确、有用的答案:"""
prompt = ChatPromptTemplate.from_template(template)
# 构建链:检索 -> 格式化 -> LLM -> 输出解析
self.chain = (
{
"context": self.retriever | self._format_docs,
"question": RunnablePassthrough(),
}
| prompt
| self.llm
| StrOutputParser()
)
@staticmethod
def _format_docs(docs: List[Document]) -> str:
"""
格式化检索到的文档
Args:
docs: 文档列表
Returns:
格式化后的字符串
"""
return "\n\n".join(doc.page_content for doc in docs)
def query(self, question: str) -> str:
"""
查询 RAG 系统
Args:
question: 用户问题
Returns:
生成的答案
"""
if self.chain is None:
raise ValueError(
"RAG 链未初始化。请先调用 build_vector_store() 或 load_vector_store()。"
)
return self.chain.invoke(question)
def add_documents(self, documents: List[Document]) -> None:
"""
向现有向量存储添加文档
Args:
documents: 新文档列表
"""
if self.vector_store is None:
raise ValueError("向量存储未初始化。请先调用 build_vector_store() 或 load_vector_store()。")
# 分割文档
split_docs = split_documents(documents)
# 添加文档到向量存储
self.vector_store.add_documents(split_docs)
# 重新创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 重新构建链
self._build_chain()
# 持久化
if self.persist:
self.vector_store.save_local(self.vector_store_path)
2.6.1 RAGChain 类初始化
class RAGChain:
def __init__(
self,
vector_store_path: Optional[str] = None,
persist: bool = True,
):
"""初始化 RAG 链"""
self.vector_store_path = vector_store_path or settings.VECTOR_STORE_PATH
self.persist = persist
self.llm = get_llm()
self.embeddings = get_embedding_model()
self.vector_store: Optional[FAISS] = None
self.retriever = None
self.chain = None
# 创建向量存储目录
Path(self.vector_store_path).mkdir(parents=True, exist_ok=True)
初始化过程:
- 设置向量存储路径(默认
./vectorstore) - 初始化 LLM 和嵌入模型
- 创建向量存储目录(如果不存在)
- 初始化向量存储、检索器和链为
None(后续构建)
2.6.2 构建向量存储:build_vector_store()
def build_vector_store(self, documents: List[Document], append: bool = False) -> None:
"""
构建向量存储
Args:
documents: 文档列表
append: 如果为 True 且向量存储已存在,则追加文档;否则覆盖
"""
if not documents:
raise ValueError("文档列表不能为空")
# 分割文档
split_docs = split_documents(documents)
# 检查向量存储是否已存在
vector_store_file = Path(self.vector_store_path) / "index.faiss"
if append and vector_store_file.exists():
# 如果启用追加模式且向量存储已存在,则加载并添加文档
print("检测到已存在的向量存储,正在加载...")
self.vector_store = FAISS.load_local(
self.vector_store_path,
self.embeddings,
allow_dangerous_deserialization=True,
)
print(f"正在添加 {len(split_docs)} 个文档块到现有向量存储...")
self.vector_store.add_documents(split_docs)
else:
# 创建新的向量存储(覆盖已存在的)
if vector_store_file.exists():
print("警告: 向量存储已存在,将被覆盖。如需增量添加,请使用 append=True 参数。")
self.vector_store = FAISS.from_documents(
documents=split_docs,
embedding=self.embeddings,
)
# 持久化
if self.persist:
self.vector_store.save_local(self.vector_store_path)
# 创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 构建 RAG 链
self._build_chain()
构建流程:
- 文档分割:将原始文档分割成小块
- 向量化:使用嵌入模型将每个文档块转换为向量
- 存储:使用 FAISS 创建向量索引并存储
- 持久化:保存到磁盘,下次可以直接加载
- 创建检索器:配置检索参数(返回 TOP_K 个最相关文档)
- 构建链:组装完整的 RAG 处理链
FAISS 简介:
- Facebook AI Similarity Search,高效的向量相似度搜索库
- 支持快速检索最相似的向量
- 支持索引持久化,可以保存和加载
2.6.3 加载向量存储:load_vector_store()
def load_vector_store(self) -> None:
"""
从磁盘加载向量存储
"""
vector_store_file = Path(self.vector_store_path) / "index.faiss"
if not vector_store_file.exists():
raise FileNotFoundError(
f"向量存储不存在: {self.vector_store_path}。请先调用 build_vector_store() 构建向量存储。"
)
self.vector_store = FAISS.load_local(
self.vector_store_path,
self.embeddings,
allow_dangerous_deserialization=True,
)
# 创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 构建 RAG 链
self._build_chain()
加载流程:
- 检查向量存储文件是否存在
- 从磁盘加载 FAISS 索引
- 重新创建检索器和 RAG 链
为什么需要加载:
- 向量存储构建耗时,避免每次都重新构建
- 支持增量更新,可以添加新文档
2.6.4 构建 RAG 链:_build_chain()
def _build_chain(self) -> None:
"""构建 RAG 链"""
# 定义提示模板
template = """基于以下上下文信息回答问题。如果上下文中没有相关信息,请说明你不知道,不要编造答案。
上下文信息:
{context}
问题:{question}
请提供准确、有用的答案:"""
prompt = ChatPromptTemplate.from_template(template)
# 构建链:检索 -> 格式化 -> LLM -> 输出解析
self.chain = (
{
"context": self.retriever | self._format_docs,
"question": RunnablePassthrough(),
}
| prompt
| self.llm
| StrOutputParser()
)
RAG 链的工作流程:
- 输入问题:用户提出问题
- 检索相关文档:
self.retriever根据问题向量检索最相关的文档片段 - 格式化文档:
self._format_docs将多个文档片段合并成字符串 - 构建提示:将上下文和问题填入提示模板
- 生成答案:LLM 基于上下文和问题生成答案
- 解析输出:
StrOutputParser将模型输出解析为字符串
提示模板的作用:
- 指导模型如何使用检索到的上下文
- 要求模型基于上下文回答,不要编造
- 提高答案的准确性和可靠性
2.6.5 格式化文档:_format_docs()
@staticmethod
def _format_docs(docs: List[Document]) -> str:
"""
格式化检索到的文档
Args:
docs: 文档列表
Returns:
格式化后的字符串
"""
return "\n\n".join(doc.page_content for doc in docs)
功能:将多个文档片段用双换行符连接,形成完整的上下文字符串。
2.6.6 查询函数:query()
def query(self, question: str) -> str:
"""
查询 RAG 系统
Args:
question: 用户问题
Returns:
生成的答案
"""
if self.chain is None:
raise ValueError(
"RAG 链未初始化。请先调用 build_vector_store() 或 load_vector_store()。"
)
return self.chain.invoke(question)
功能:执行完整的 RAG 流程,返回答案。
2.6.7 添加文档:add_documents()
def add_documents(self, documents: List[Document]) -> None:
"""
向现有向量存储添加文档
Args:
documents: 新文档列表
"""
if self.vector_store is None:
raise ValueError("向量存储未初始化。请先调用 build_vector_store() 或 load_vector_store()。")
# 分割文档
split_docs = split_documents(documents)
# 添加文档到向量存储
self.vector_store.add_documents(split_docs)
# 重新创建检索器
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": settings.TOP_K}
)
# 重新构建链
self._build_chain()
# 持久化
if self.persist:
self.vector_store.save_local(self.vector_store_path)
功能:支持向已有向量存储添加新文档,实现知识库的增量更新。
2.7 主程序模块详解(main.py)
主程序提供了命令行接口,支持三种运行模式。
完整样例代码
"""
RAG 系统主程序入口
"""
import argparse
from pathlib import Path
from chains import RAGChain
from utils import load_documents
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="RAG 系统 - 检索增强生成")
parser.add_argument(
"--mode",
type=str,
choices=["build", "query", "interactive"],
default="interactive",
help="运行模式: build(构建向量存储), query(单次查询), interactive(交互模式)",
)
parser.add_argument(
"--file",
type=str,
help="要加载的文档文件路径(用于 build 模式)",
)
parser.add_argument(
"--question",
type=str,
help="要查询的问题(用于 query 模式)",
)
parser.add_argument(
"--vector-store",
type=str,
default="./vectorstore",
help="向量存储路径",
)
parser.add_argument(
"--append",
action="store_true",
help="增量添加模式:如果向量存储已存在,则追加文档而不是覆盖(仅用于 build 模式)",
)
args = parser.parse_args()
# 初始化 RAG 链
rag = RAGChain(vector_store_path=args.vector_store)
if args.mode == "build":
# 构建模式:加载文档并构建向量存储
if not args.file:
print("错误: build 模式需要指定 --file 参数")
return
print(f"正在加载文档: {args.file}")
documents = load_documents(args.file)
print(f"已加载 {len(documents)} 个文档")
if args.append:
print("使用增量添加模式...")
else:
print("正在构建向量存储...")
rag.build_vector_store(documents, append=args.append)
print(f"向量存储已构建并保存到: {args.vector_store}")
elif args.mode == "query":
# 查询模式:单次查询
if not args.question:
print("错误: query 模式需要指定 --question 参数")
return
print("正在加载向量存储...")
try:
rag.load_vector_store()
except FileNotFoundError:
print("错误: 向量存储不存在。请先使用 build 模式构建向量存储。")
return
print(f"问题: {args.question}")
print("正在生成答案...")
answer = rag.query(args.question)
print(f"\n答案:\n{answer}")
elif args.mode == "interactive":
# 交互模式:持续对话
print("正在加载向量存储...")
try:
rag.load_vector_store()
except FileNotFoundError:
print("错误: 向量存储不存在。请先使用 build 模式构建向量存储。")
print("示例命令: python main.py --mode build --file your_document.txt")
return
print("RAG 系统已就绪!输入 'quit' 或 'exit' 退出。\n")
while True:
question = input("请输入您的问题: ").strip()
if question.lower() in ["quit", "exit", "退出"]:
print("再见!")
break
if not question:
continue
try:
print("正在生成答案...")
answer = rag.query(question)
print(f"\n答案:\n{answer}\n")
except Exception as e:
print(f"错误: {e}\n")
if __name__ == "__main__":
main()
2.7.1 命令行参数解析
parser = argparse.ArgumentParser(description="RAG 系统 - 检索增强生成")
parser.add_argument(
"--mode",
type=str,
choices=["build", "query", "interactive"],
default="interactive",
help="运行模式: build(构建向量存储), query(单次查询), interactive(交互模式)",
)
parser.add_argument(
"--file",
type=str,
help="要加载的文档文件路径(用于 build 模式)",
)
parser.add_argument(
"--question",
type=str,
help="要查询的问题(用于 query 模式)",
)
parser.add_argument(
"--vector-store",
type=str,
default="./vectorstore",
help="向量存储路径",
)
parser.add_argument(
"--append",
action="store_true",
help="增量添加模式:如果向量存储已存在,则追加文档而不是覆盖(仅用于 build 模式)",
)
args = parser.parse_args()
支持的参数:
--mode: 运行模式(build/query/interactive)--file: 文档文件路径(build 模式必需)--question: 查询问题(query 模式必需)--vector-store: 向量存储路径(可选,默认./vectorstore)
2.7.2 构建模式(build)
if args.mode == "build":
# 构建模式:加载文档并构建向量存储
if not args.file:
print("错误: build 模式需要指定 --file 参数")
return
print(f"正在加载文档: {args.file}")
documents = load_documents(args.file)
print(f"已加载 {len(documents)} 个文档")
if args.append:
print("使用增量添加模式...")
else:
print("正在构建向量存储...")
rag.build_vector_store(documents, append=args.append)
print(f"向量存储已构建并保存到: {args.vector_store}")
功能:
- 加载指定文档
- 构建向量存储
- 保存到指定路径
使用示例:
python main.py --mode build --file kb.txt
2.7.3 查询模式(query)
elif args.mode == "query":
# 查询模式:单次查询
if not args.question:
print("错误: query 模式需要指定 --question 参数")
return
print("正在加载向量存储...")
try:
rag.load_vector_store()
except FileNotFoundError:
print("错误: 向量存储不存在。请先使用 build 模式构建向量存储。")
return
print(f"问题: {args.question}")
print("正在生成答案...")
answer = rag.query(args.question)
print(f"\n答案:\n{answer}")
功能:
- 加载已有向量存储
- 执行单次查询
- 输出答案
使用示例:
python main.py --mode query --question "希冀平台是什么?"
2.7.4 交互模式(interactive)
elif args.mode == "interactive":
# 交互模式:持续对话
print("正在加载向量存储...")
try:
rag.load_vector_store()
except FileNotFoundError:
print("错误: 向量存储不存在。请先使用 build 模式构建向量存储。")
print("示例命令: python main.py --mode build --file your_document.txt")
return
print("RAG 系统已就绪!输入 'quit' 或 'exit' 退出。\n")
while True:
question = input("请输入您的问题: ").strip()
if question.lower() in ["quit", "exit", "退出"]:
print("再见!")
break
if not question:
continue
try:
print("正在生成答案...")
answer = rag.query(question)
print(f"\n答案:\n{answer}\n")
except Exception as e:
print(f"错误: {e}\n")
功能:
- 启动交互式对话循环
- 持续接收用户问题
- 实时生成答案
- 支持退出命令(quit/exit/退出)
使用示例:
python main.py --mode interactive
2.8 实验步骤1:安装依赖
首先,需要安装项目依赖。在项目根目录下运行:
pip install -r requirements.txt
依赖说明:
langchain: LangChain 核心库langchain-openai: OpenAI 兼容接口langchain-community: 社区扩展(包含文档加载器等)faiss-cpu: FAISS 向量数据库(CPU 版本)pydantic-settings: 配置管理pypdf: PDF 文件处理
2.9 实验步骤2:构建向量存储
使用提供的知识库文件 kb.txt 构建向量存储:
python main.py --mode build --file kb.txt
# ppython main.py --mode build --file 2026年本科直博研究生招生专业目录.pdf --append
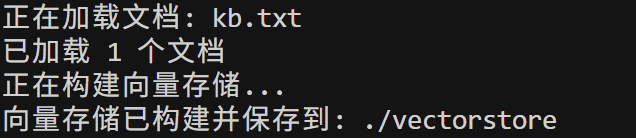
执行过程:
- 加载
kb.txt文件 - 将文档分割成小块
- 使用嵌入模型将每个块转换为向量
- 使用 FAISS 创建向量索引
- 保存到
vectorstore/目录
2.10 实验步骤3:交互式查询
构建向量存储后,启动交互式查询:
python main.py --mode interactive
2.11 实验步骤4:单次查询
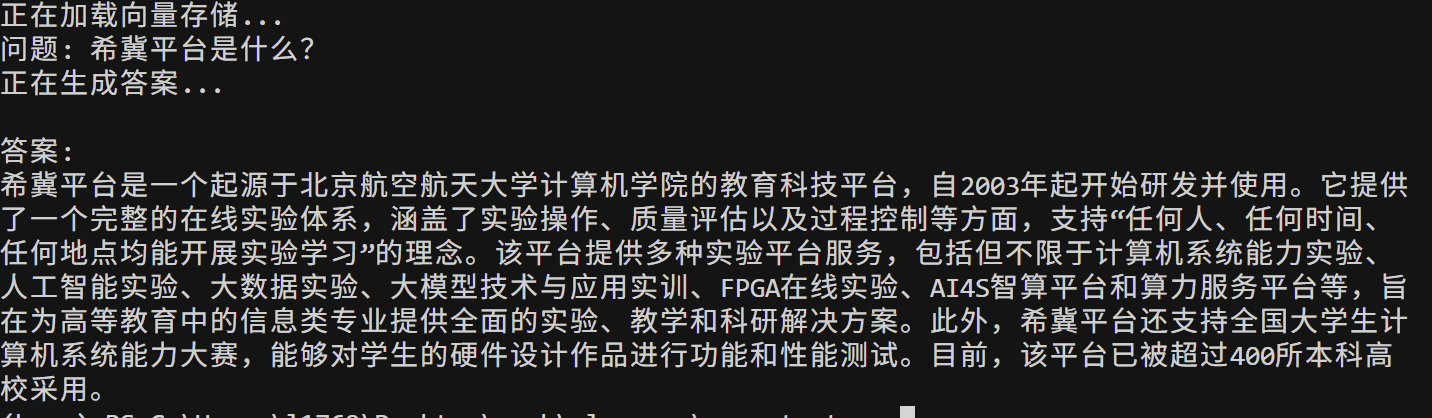
也可以使用单次查询模式:
python main.py --mode query --question "希冀平台是什么?"
# python main.py --mode query --question "2026江南大学本科直博研究生招生专业目录中,食品学院的招生专业有哪些?"
2.12 实验步骤5:使用自定义文档
可以使用自己的文档构建知识库。支持的文件格式:
.txt: 纯文本文件.pdf: PDF 文件.md/.markdown: Markdown 文件
示例:
# 使用 PDF 文件
python main.py --mode build --file your_document.pdf
# 使用 Markdown 文件
python main.py --mode build --file your_document.md
三、实验任务
3.1 基础任务
参考实验步骤,完成以下任务:
- 环境搭建:安装所有依赖,确保系统可以正常运行
- 向量存储构建:使用
kb.txt构建向量存储,观察构建过程和输出信息 - 交互式查询:启动交互模式,尝试提出不同类型的问题,观察系统回答的质量
- 单次查询测试:使用 query 模式测试不同的问题,记录答案质量
3.2 扩展任务
- 使用自定义知识库:
- 准备一个自己感兴趣领域的文档(如技术文档、学术论文、校园通知等)
- 使用该文档构建向量存储
- 测试系统对该领域问题的回答能力
- 参数调优实验:
- 修改
config/settings.py中的CHUNK_SIZE和CHUNK_OVERLAP参数 - 观察不同参数对检索效果的影响
- 修改
TOP_K参数,观察返回文档数量对答案质量的影响
- 修改
- 多文档知识库:
- 查阅文档,思考如何支持word、excel文档的检索
- 修改代码,尝试实现
- 尝试支持不
3.3 实验报告要求
撰写实验报告,需要在实验报告中完成以下任务:
- 实验过程记录:
- 记录完整的实验步骤,包括环境搭建、向量存储构建、查询测试等
- 提供关键步骤的截图或输出结果
- 记录使用自定义文档的实验过程和结果
- 代码理解分析:
- 分析每个模块的功能和实现原理
- 说明 RAG 系统的工作流程
- 解释向量检索和答案生成的过程
- 思考题:
- 思考题1:RAG 系统相比直接使用大语言模型有什么优势和局限性?请从准确性、实时性、成本等角度进行分析
- 思考题2:文档分割策略(chunk_size 和 chunk_overlap)对检索效果有什么影响?如何选择合适的参数?
- 思考题3:RAG 技术在哪些领域有潜在应用?请结合你的专业背景,谈谈 RAG 技术如何解决实际问题
- 问题与改进:
- 记录实验过程中遇到的问题和解决方法
- 提出对系统的改进建议
- 思考如何优化检索效果和答案质量